

近日,中國科學(xué)院聲學(xué)研究所(以下簡(jiǎn)稱聲學(xué)所)噪聲與音頻聲學(xué)實(shí)驗(yàn)室鄭成詩研究員研究團(tuán)隊(duì)在聽覺領(lǐng)域期刊Trends in Hearing (中國科學(xué)院期刊分區(qū)一區(qū)top)發(fā)表綜述:Sixty Years of Frequency-Domain Monaural Speech Enhancement: From Traditional to Deep Learning Methods (時(shí)頻域單通道語音增強(qiáng)60年——從傳統(tǒng)方法到深度學(xué)習(xí)方法)。聲學(xué)所鄭成詩研究員、英國劍橋大學(xué)教授Brian C. J. Moore和聲學(xué)所博士研究生羅笑雪為該綜述共同一者,鄭成詩研究員為論文通訊作者,聲學(xué)所噪聲與音頻聲學(xué)實(shí)驗(yàn)室為論文第一單位。該綜述全面概述了時(shí)頻域單通道語音增強(qiáng)60年發(fā)展歷程的傳統(tǒng)方法和深度學(xué)習(xí)方法:首先總結(jié)和分析了兩類方法的基本假設(shè),闡明了各自的優(yōu)勢(shì)和局限性;接著,使用相同的語料庫比較兩類共計(jì)十余種有代表性的方法處理性能,通過客觀評(píng)價(jià)方法評(píng)估了不同方法對(duì)正常聽力人群和聽力受損人群的不同作用;最后總結(jié)了現(xiàn)有單通道語音增強(qiáng)方法在助聽領(lǐng)域應(yīng)用所面臨的挑戰(zhàn)及未來發(fā)展趨勢(shì)。

近60年,研究人員對(duì)時(shí)頻域單通道語音增強(qiáng)技術(shù)進(jìn)行了廣泛的研究。早期由于計(jì)算性能限制和淺層神經(jīng)網(wǎng)絡(luò)泛化能力較弱,對(duì)時(shí)頻域單通道語音增強(qiáng)技術(shù)的研究主要集中于傳統(tǒng)信號(hào)處理的方法。大量的經(jīng)典傳統(tǒng)方法被提出并成功應(yīng)用于許多音頻設(shè)備中。近十年來,隨著深度學(xué)習(xí)的出現(xiàn)和發(fā)展,神經(jīng)網(wǎng)絡(luò)建模能力和泛化性能的提升,單通道語音增強(qiáng)技術(shù)性能實(shí)現(xiàn)了較大的飛躍。雖然目前已有許多關(guān)于傳統(tǒng)方法或深度學(xué)習(xí)方法的綜述論文和書籍出版,但這些綜述并未將兩類方法進(jìn)行綜合分析,也未深入揭示兩類方法的各自優(yōu)缺點(diǎn),同時(shí)也沒有對(duì)目前主流的時(shí)頻域單通道語音增強(qiáng)技術(shù)進(jìn)行同數(shù)據(jù)集下的綜合性能比較。
在本綜述中,研究人員回顧了過去六十年來提出的許多具有代表性的時(shí)頻域單通道語音增強(qiáng)方法。其中,傳統(tǒng)單通道語音增強(qiáng)方法的流程圖如圖1所示。傳統(tǒng)方法通常不是數(shù)據(jù)驅(qū)動(dòng)的,往往依賴于語音和噪聲的特定統(tǒng)計(jì)模型和/或語音的確定性模型。本綜述主要從傳統(tǒng)語音增強(qiáng)算法可能使用的各模塊入手進(jìn)行梳理總結(jié)。其主要包括:噪聲估計(jì)、先驗(yàn)信噪比估計(jì)、語音存在概率估計(jì)、譜增益估計(jì)、相位處理等。對(duì)于大多數(shù)傳統(tǒng)的頻域語音增強(qiáng)方法來說,有四個(gè)基本假設(shè):第一,語音和噪聲在統(tǒng)計(jì)上是獨(dú)立的;第二,噪聲比語音更平穩(wěn);第三,在特定統(tǒng)計(jì)模型下推導(dǎo)頻譜增益函數(shù)時(shí),每個(gè)時(shí)頻點(diǎn)頻譜在統(tǒng)計(jì)上相互獨(dú)立;第四,語音相位不如語音幅度譜重要。僅有第一個(gè)假設(shè)是合理的,其他三個(gè)假設(shè)并不合理,這也就限制了傳統(tǒng)算法的應(yīng)用場(chǎng)景,并約束了基于這些假設(shè)的方法的性能上限。
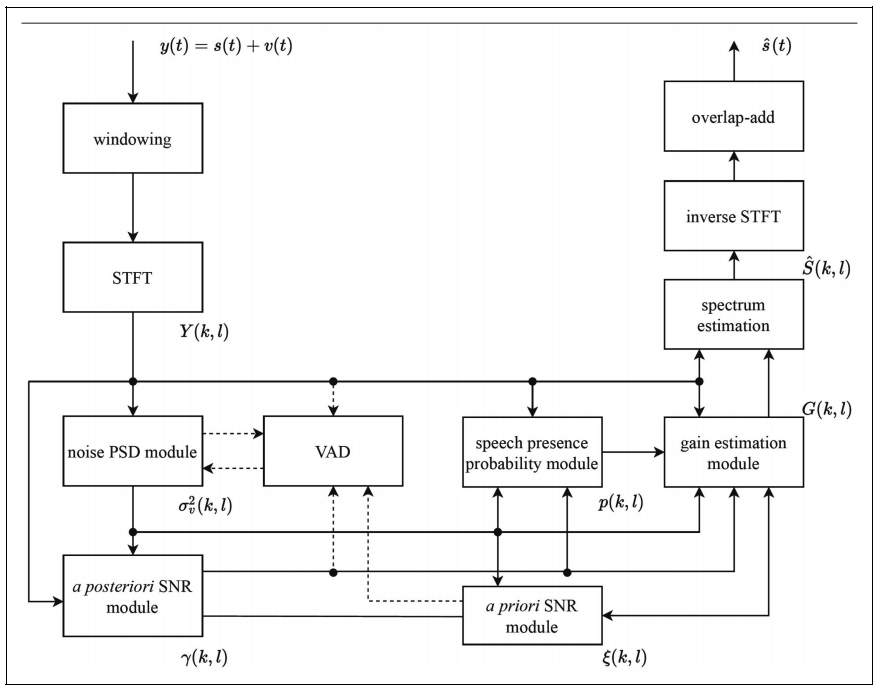
圖1?傳統(tǒng)單通道語音增強(qiáng)方法的流程圖。(圖/中國科學(xué)院聲學(xué)研究所)
相比之下,深度學(xué)習(xí)方法通常由數(shù)據(jù)驅(qū)動(dòng),其性能取決于訓(xùn)練數(shù)據(jù)集、提供的輸入特征、學(xué)習(xí)目標(biāo)和深度學(xué)習(xí)網(wǎng)絡(luò)架構(gòu)。基于深度學(xué)習(xí)的單通道語音增強(qiáng)方法的基本流程圖如圖2所示。這類方法通常包括兩個(gè)階段:訓(xùn)練和測(cè)試。本綜述對(duì)兩個(gè)階段中可能使用的模塊分別進(jìn)行了梳理總結(jié),其分別為:特征提取、網(wǎng)絡(luò)結(jié)構(gòu)、學(xué)習(xí)目標(biāo)和損失函數(shù)。值得一提的是,由于基于深度學(xué)習(xí)的單通道語音增強(qiáng)方法是由數(shù)據(jù)驅(qū)動(dòng)的,這一"黑箱"性質(zhì)側(cè)面反映了這些深度學(xué)習(xí)方法的一個(gè)缺點(diǎn):研究人員很難詳細(xì)了解深度學(xué)習(xí)是如何實(shí)現(xiàn)其結(jié)果的,也很難解釋改變 深度學(xué)習(xí)架構(gòu)所產(chǎn)生的性能變化。
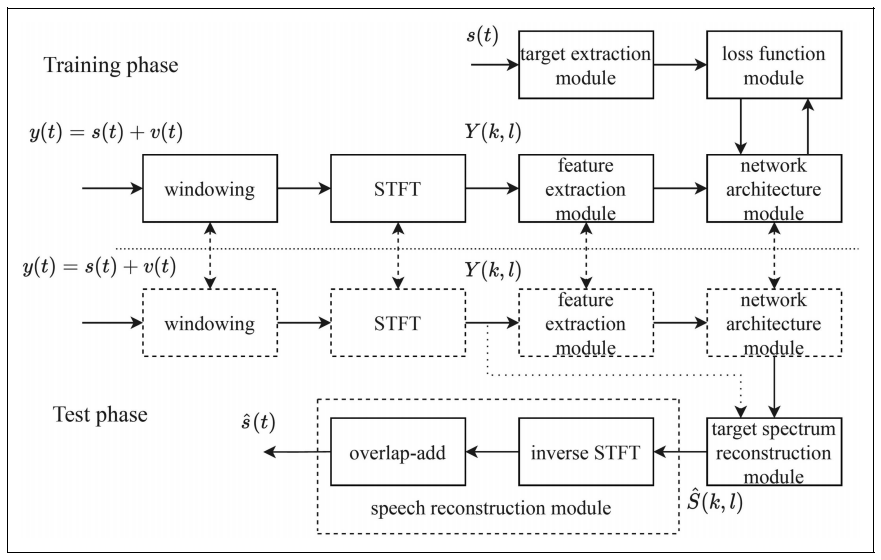
圖2?基于深度學(xué)習(xí)的單通道語音增強(qiáng)方法的流程圖。(圖/中國科學(xué)院聲學(xué)研究所)
盡管傳統(tǒng)方法和深度學(xué)習(xí)方法截然不同,但后者深受前者的影響。此外,還有一些深度學(xué)習(xí)與傳統(tǒng)方法融合的混合方法(Hybrid Method),通過深度學(xué)習(xí)直接映射傳統(tǒng)方法需要的關(guān)鍵參數(shù),例如語音和噪聲的功率譜估計(jì)和先驗(yàn)信噪比估計(jì)等。這些混合方法綜合傳統(tǒng)算法和深度學(xué)習(xí)算法的優(yōu)勢(shì),可以在相對(duì)有限的計(jì)算資源下達(dá)到一個(gè)較好的性能。
不同聽力受損人群對(duì)算法設(shè)計(jì)需求往往也不同,本綜述使用 WSJ + DNS和 Voice Bank + DEMAND 數(shù)據(jù)集對(duì)一些傳統(tǒng)和深度學(xué)習(xí)的典型方法進(jìn)行了綜合評(píng)估,對(duì)兩類代表性方法的性能進(jìn)行直觀統(tǒng)一的比較。本綜述采用了與正常聽力人群和聽力受損人群相關(guān)的客觀指標(biāo)(HASQI和HASPI)對(duì)兩類方法進(jìn)行了綜合測(cè)試,客觀測(cè)試結(jié)果表明:
????隨著聽力損失的增加,語音質(zhì)量會(huì)提高,而語音可懂度會(huì)降低;
????輸入特征的壓縮對(duì)模擬正常聽力人群重要,但對(duì)模擬聽力受損人群并不重要;
????對(duì)于模擬正常聽力/聽力受損人群,基于深度學(xué)習(xí)的方法處理結(jié)果都相較傳統(tǒng)算法有更好的性能體現(xiàn)。
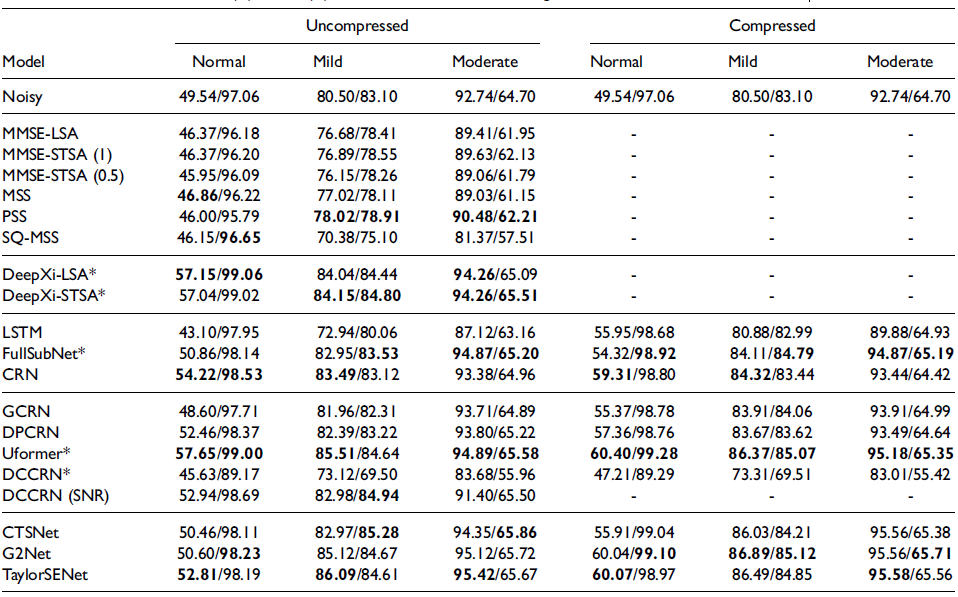
圖3 Voice Bank + DEMAND 數(shù)據(jù)集下不同方法的HASPI(%)和HASQI(%)得分。(圖/中國科學(xué)院聲學(xué)研究所)
本綜述回顧了過去六十年來提出的許多具有代表性的時(shí)頻域單聲道語音增強(qiáng)方法,主要包括傳統(tǒng)信號(hào)處理方法和基于深度學(xué)習(xí)的方法。未來可研究探索的挑戰(zhàn)和方向包括:1)研究具有可解釋內(nèi)在機(jī)制的深度學(xué)習(xí)單通道語音增強(qiáng)算法;2)結(jié)合傳統(tǒng)算法降低深度學(xué)習(xí)方法的復(fù)雜度、存儲(chǔ)量、時(shí)間延遲;3)開展聽力正常人群和不同聽力受損人群的主觀測(cè)評(píng)工作。
本研究得到國家重點(diǎn)研發(fā)計(jì)劃項(xiàng)目(No.2021YFB3201702)資助。
關(guān)鍵詞:
語音增強(qiáng);語音去混響;多階段學(xué)習(xí);噪聲估計(jì);深度復(fù)數(shù)網(wǎng)絡(luò)
參考文獻(xiàn):
Zheng, C., Zhang, H., Liu, W., Luo, X., Li, A., Li, X., & Moore, B. C. (2023). Sixty years of frequency-domain monaural speech enhancement: From traditional to deep learning methods.?Trends in Hearing,?27, 23312165231209913.?DOI:?10.1177/23312165231209913
論文鏈接:
https://journals.sagepub.com/doi/full/10.1177/23312165231209913
相關(guān)開源代碼鏈接:
https://github.com/cszheng-ioa/Sixty-years-of-frequency-domain-monaural-speech-enhancement